Abstract
Trajectory prediction is an important task in many real-world applications. However, data-driven approaches typically suffer from dramatic performance degradation when applied to unseen environments due to the inevitable domain shift brought by changes in factors such as pedestrian walking speed, the geometry of the environment, etc. In particular, when a dataset does not contain sufficient samples to determine prediction rules, the trained model can easily consider some important features as domain variant. We propose a framework that integrates a simple motion prior with deep learning to achieve, for the first time, exceptional single-source domain generalisation for trajectory prediction, in which deep learning models are only trained using a single domain and then applied to multiple novel domains. Instead of predicting the exact future positions directly from the model, we first assign a constant velocity motion prior to each pedestrian and then learn a conditional trajectory prediction model to predict residuals to the motion prior using auxiliary information from the surrounding environment. This strategy combines deep learning models with knowledge priors to simultaneously simplify training and enhance generalisation, allowing the model to focus on disentangling data-driven spatio-temporal factors while not overfitting to individual motions. We also propose a novel Train-on-Best-Motion strategy that can alleviate the adverse effects of domain shift, brought on by changes in environment, by exploiting invariances inherent to the choice of motion prior. Experiments across multiple datasets of different domains demonstrate that our approach reduces the influence of domain shift and also generalizes better to unseen environments. URL
Model Architecture
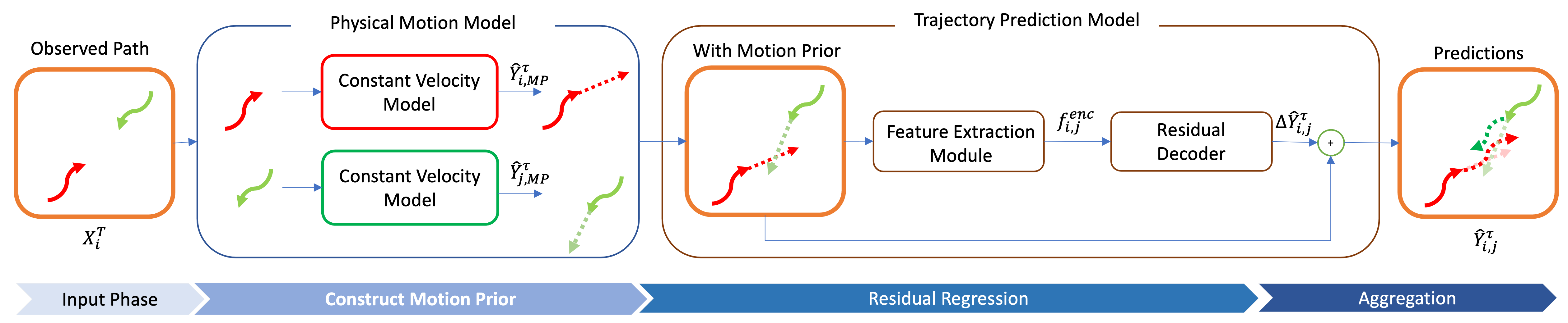
Given pedestrians’ observed trajectories, we first assign a motion prior using a physical motion model. Then we send them together with observed trajectories into a deep learning based trajectory prediction model to predict the residuals. The final prediction is the aggregation between the motion prior and the residuals.
Overall Results
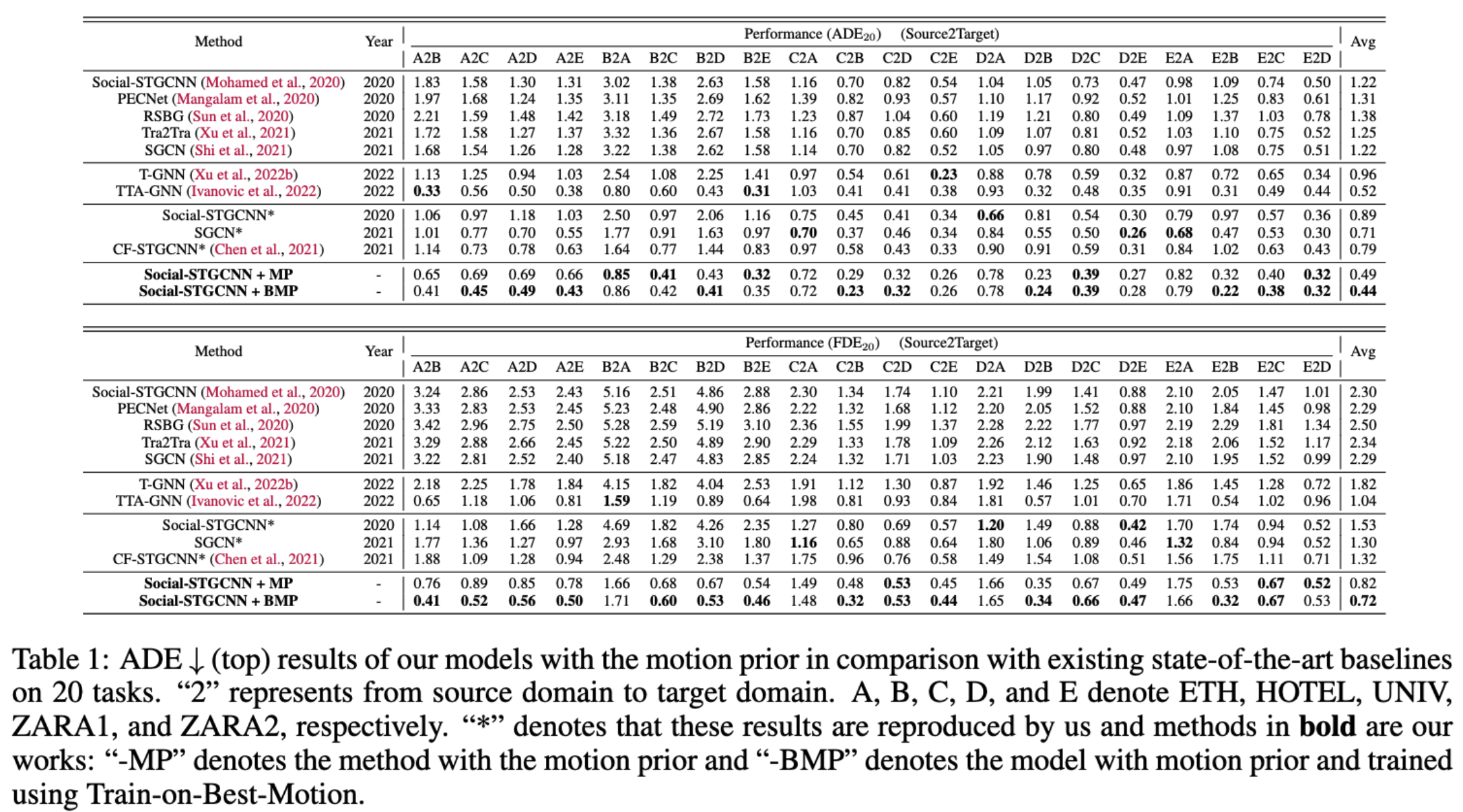
The performance of our methods against our basesline as shown above. Our method that integrates a motion prior can outperform all baselines across different datasets, indicating the effectiveness of integrating motion priors alongside a deep learning model. A better performance of +10.2% can be achieved when using Train-on-Best-Motion which reaches state-of-the-art in this benchmark. Specifically, our model outperforms T-GNN by around 50% and the current state-of-the-art model TTA-GNN by around 6%, which validates that our method can be even better than current single source domain adaptation methods. Domains such as Hotel (B) contain different trajectories to others and hence the performance gaps between D2B and C2B using T-GNN and TTA-GNN are around 0.24/0.34 and 0.09/0.25 of ADE/FDE respectively. On the other hand, our method only produces a difference of only 0.06/0.13 in ADE/FDE after adding the motion and 0.01/0.02 after using the ``Train-on-Best-Motion’’, which indicates our model can generalise better to unseen domains. We also note that our method is better than SF-STGCNN. A plausible reason is that the motion prior can be more direct and effective in reducing model overfitting than counterfactual learning.
Visualisation
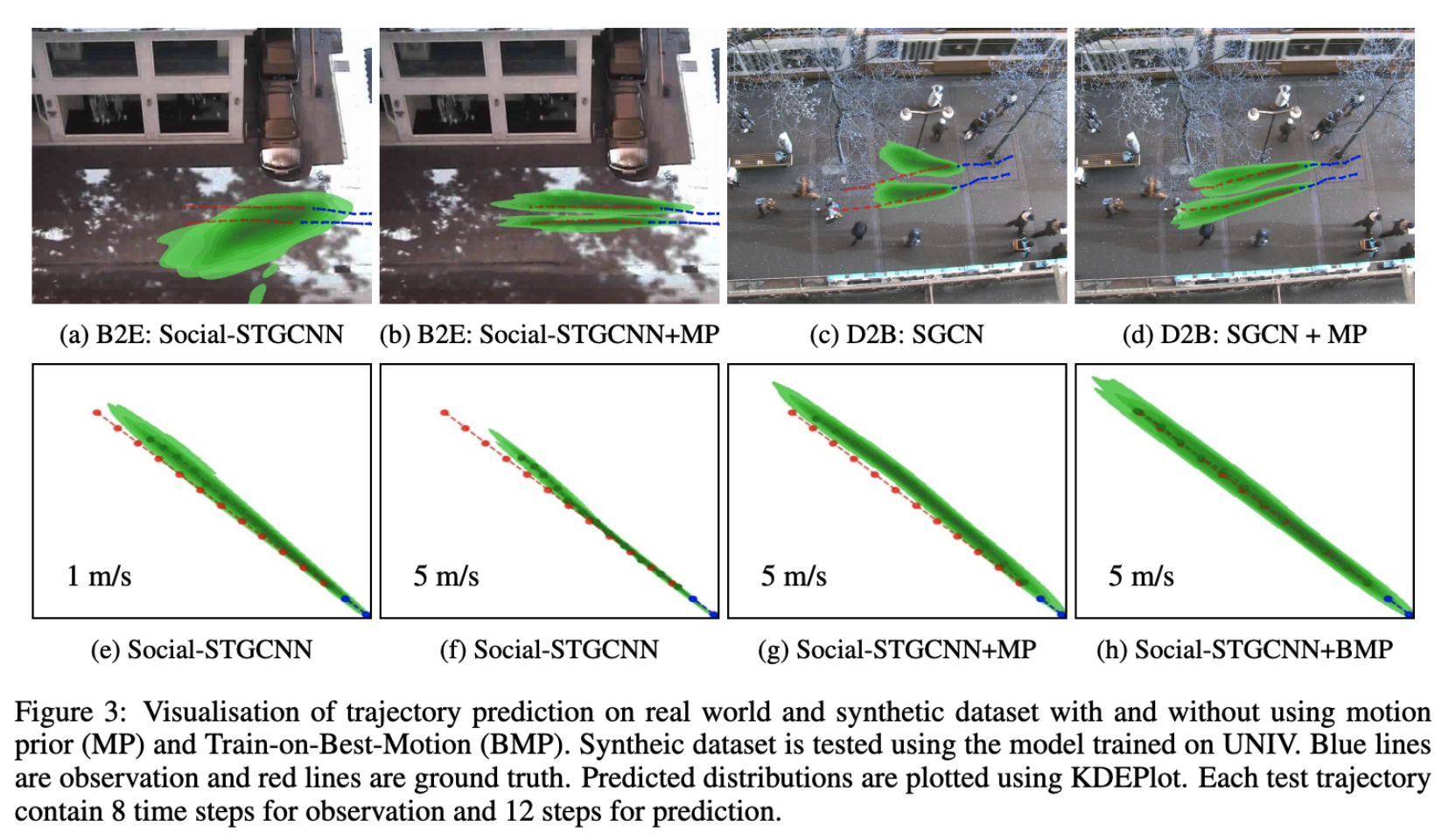
BibTex
@InProceedings{mp-traj,
author = {Huang, Renhao and Tompkins, Anthony and Pagnucco, Maurice and Song, Yang},
title = {Towards Single Source Domain Generalisation in Trajectory Prediction: A Motion Prior based Approach},
booktitle = {Conference on Lifelong Learning Agents},
year = {2023},
}